机器性能指标
CPU(Load) CPU使用率/负载
Memory 内存
Disk 磁盘空间
Disk I/O 磁盘I/O
Network I/O 网络I/O
Connect Num 连接数
File Handle Num 文件句柄数
CPU
1.说明
机器的CPU占有率越高,说明机器处理越忙,运算型任务越多。一个任务可能不仅会有运算部分,还会有I/O(磁盘I/O与网络I/O)部分,当在处理I/O时,时间片未完其CPU也会释放,因此某个时间点的CPU占有率没有太大的意义,因此需要计算一段时间内的平均值,那么平均负载(Load Average)这个指标便能很好得对其进行表征。平均负载:它是根据一段时间内占有CPU的进程数目和等待CPU的进程数目计算出来的,其中等待CPU的进程不包括处于wait状态的进程,比如在等待I/O的进程,即指那些就绪状态的进程,运行只缺CPU这个资源。具体如何计算可以参见Linux内核代码,计算出一个数之后,然后除以CPU核数,结果:
<=3 则系统性能较好。
<=4 则系统性能可以,可以接收。
>5 则系统性能负载过重,可能会发生严重的问题,那么就需要扩容了,要么增加核,要么分布式集群。
2.查看命令
2.1 vmstat n m
n表示每隔n秒采集一次,m表示一共采集多少次,如果m没有,那么会一直采集下去. 在终端键入 vmstat 5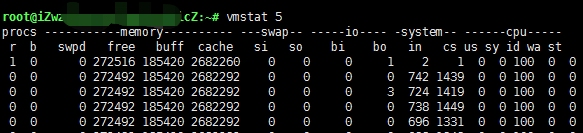
结果各字段解释如下(这里只解释与CPU相关的):
r:表示运行队列(就是说多少个进程真的分配到CPU),当这个值超过了CPU数目,就会出现CPU瓶颈了。这个也和top的负载有关系,一般负载超过了3就比较高,超过了5就高,超过了10就不正常了,服务器的状态很危险。top的负载类似每秒的运行队列。如果运行队列过大,表示你的CPU很繁忙,一般会造成CPU使用率很高。
b:表示阻塞的进程,如在等待I/O请求。
in:每秒CPU的中断次数,包括时间中断。
cs:每秒上下文切换次数,例如我们调用系统函数,就要进行上下文切换,线程的切换,也要进程上下文切换,这个值要越小越好,太大了,要考虑调低线程或者进程的数目,例如在apache和nginx这种web服务器中,我们一般做性能测试时会进行几千并发甚至几万并发的测试,选择web服务器的进程可以由进程或者线程的峰值一直下调,压测,直到cs到一个比较小的值,这个进程和线程数就是比较合适的值了。系统调用也是,每次调用系统函数,我们的代码就会进入内核空间,导致上下文切换,这个是很耗资源,也要尽量避免频繁调用系统函数。上下文切换次数过多表示你的CPU大部分浪费在上下文切换,导致CPU干正经事的时间少了,CPU没有充分利用,是不可取的。
us:用户CPU时间占比(%),例如在做高运算的任务时,如加密解密,那么会导致us很大,这样,r也会变大,造成系统瓶颈。
sy:系统CPU时间占比(%),如果太高,表示系统调用时间长,如IO频繁操作。
id :空闲 CPU时间占比(%),一般来说,id + us + sy = 100,一般认为id是空闲CPU使用率,us是用户CPU使用率,sy是系统CPU使用率。
wt:等待IO的CPU时间。
2.2 uptime
![]()
23:25:07 为当前时间
up 81 days, 6:23 机器运行时间,时间越大说明你的机器越稳定
2 users 用户连接数,而不是总用户数
load average: 0.00, 0.00, 0.00 最近1分钟,5分钟,15分钟的系统平均负载。
将平均负载值除以核数,如果结果不大于3,那么系统性能较好,如果不大于4那么系统性能可以接受,如果大于5,那么系统性能较差。
2.3 top 命令
top命令用于显示进程信息,top详细见 http://www.cnblogs.com/peida/archive/2012/12/24/2831353.html
这里主要关注Cpu(s)统计那一行:
us:用户空间占用CPU的百分比
sy:内核空间占用CPU的百分比
ni:改变过优先级的进程占用CPU的百分比
id: 空闲CPU百分比
wa: IO等待占用CPU的百分比
hi:硬中断(Hardware IRQ)占用CPU的百分比
si:软中断(Software Interrupts)占用CPU的百分比
从top的结果看CPU负载情况,主要看us和sy,其中us<=70,sy<=35,us+sy<=70说明状态良好,同时可以结合idle值来看,如果id<=70 则表示IO的压力较大。也可以和uptime一样,看第一行。引用[1]
下面是yuyue服务器的一次案例,us占到50.8 ,已经比较高了
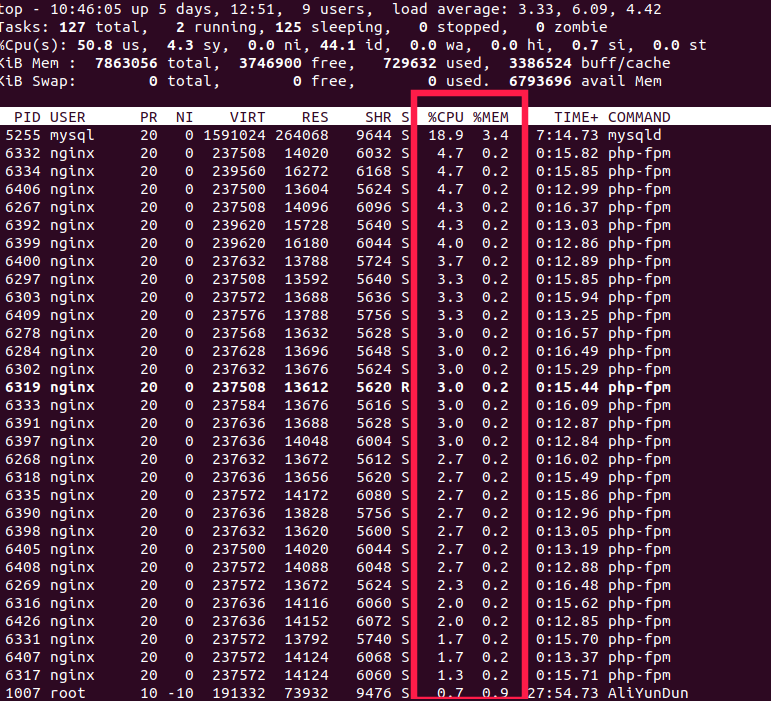
直接导致服务挂掉的情况(真实案例)

3. 分析
表示系统CPU正常,主要有以下规则:
CPU利用率:us <= 70,sy <= 35,us + sy <= 70。引用[1]
上下文切换:与CPU利用率相关联,如果CPU利用率状态良好,大量的上下文切换也是可以接受的。引用[1]
可运行队列:每个处理器的可运行队列<=3个线程。
Memory
1.说明
内存也是系统运行性能的一个很重要的指标,如果一个机器内存不足,那么将会导致进程运行异常而退出。如果进程发生内存泄漏,则会导致大量内存被浪费而无足够可用内存。内存监控一般包括total(机器总内存)、free(机器可用内存)、swap(交换区大小)、cache(缓存大小)等。
2.命令
2.1 vmstat
结果各字段解释如下(这里只解释与Memory相关的):
swpd:虚拟内存已使用的大小,如果大于0,表示你的机器物理内存不足了,如果不是程序内存泄露的原因,那么你该升级内存了或者把耗内存的任务迁移到其他机器,单位为KB。
free :空闲的物理内存的大小,我的机器内存总共8G,剩余4457612KB,单位为KB。
buff:Linux/Unix系统来存储目录里面有什么内容,权限等的缓存,这里大概占用280M,单位为KB。
cache:cache直接用来记忆我们打开的文件,给文件做缓冲,这里大概占用280M(这里是Linux/Unix的聪明之处,把空闲的物理内存的一部分拿来做文件、目录和进程地址空间的缓存,是为了提高程序执行的性能,当程序使用内存时,buffer/cached会很快地被使用),单位为KB。
si: 每秒从磁盘读入虚拟内存的大小,如果这个值大于0,表示物理内存不够用或者内存泄露了,要查找耗内存进程解决掉。本机内存充裕,一切正常,单位为KB。
so:每秒虚拟内存写入磁盘的大小,如果这个值大于0,同上,单位为KB。
2.2 free
第二行是内存信息,total为机器总内存,used为多少已经使用,free为多少空闲,shared为多个进程共享的内存总额,buffers与cache都是磁盘缓存的大小,分别同vmstat里面的buff与cache. 单位都是M.
第三行是buffers与cache总额的used与free. 单位都是M.
第四行是交换区swap的总额、已用与free. 单位都是M.
区别:第二行(mem)的used/free与第三行(-/+ buffers/cache) used/free的区别。 这两个的区别在于使用的角度来看,第二行是从OS的角度来看,因为对于OS,buffers/cached 都是属于被使用,所以他的可用内存是4353M, 已用内存是3519M, 其中包括,内核(OS)使用+Application(X, oracle,etc)使用的+buffers+cached.
第三行所指的是从应用程序角度来看,对于应用程序来说,buffers/cached 是等于可用的,因为buffer/cached是为了提高文件读取的性能,当应用程序需在用到内存的时候,buffer/cached会很快地被回收。
所以从应用程序的角度来说,可用内存=系统free memory+buffers+cached。
2.3 top
只关注与内存相关的统计信息,即Mem与Swap行。分别是Mem与Swap的总额、已用量、空闲量、buffers与cache. 这里便验证了buffers是缓存目录里面有什么内容,权限等信息的,而cache是用来swap的缓存的.
2.4 cat /proc/meminfo
主要这几个字段:
MemTotal:内存总额
MemFree:内存空闲量
Buffers:同top命令的buffers
Cached:同top命令的cache
SwapToatl:Swap区总大小
SwapFree:Swap区空闲大小
分析
表示系统Mem正常,主要有以下规则:
swap in (si) == 0,swap out (so) == 0
可用内存/物理内存 >= 30%
磁盘
1.说明
机器的磁盘空间也是一个重要的指标,一旦使用率超过阈值而使得可用不足,那么就需要进行扩容或者清除一些无用的文件。
2. 查看命令
2.1df
Filesystem:文件系统的名称
1K-blocks:1K块的文件系统
Used:已使用量,单位为KB
Available:空闲量,单位为KB
Use%:已使用占比
Mounted on:挂载的目录
3. 分析
表示系统磁盘空间正常,主要有以下规则:
Use% <= 90%
磁盘I/O
1.说明
机器的磁盘空间也是一个重要的指标,一旦磁盘I/O过重,那么说明运行的进程在大量的文件读写并且cache命中率低。那么一个简单的方法便是增大文件缓存大小来提高命中率从而降低I/O。
在Linux中,内核希望能尽可能产生次缺页中断(从文件缓存区读),并且能尽可能避免主缺页中断(从硬盘读),这样随着缺页中断的增多,文件缓存区也逐步增大,直到系统只有少量可用物理内存的时候 Linux 才开始释放一些不用的页。引用[1]
2. 查看命令
2.1 vmstat
bi :块设备每秒接收的块数量,这里的块设备是指系统上所有的磁盘和其他块设备,默认块大小1024byte。
bo:块设备每秒发送的块数量,例如我们读取文件,bo就要大于0。bi和bo一般都要接近0,不然就是IO过于频繁,需要调整。
2.2 iostat
Linux段为机器系统信息: 系统名称、hostname、当前时间、系统版本.
avg-cpu段为cpu的统计信息(平均值):
%user:用户级别运行所使用的CPU的百分比.
%nice:nice操作所使用的CPU的百分比.
%sys:在系统级别(kernel)运行所使用CPU的百分比.
%iowait:CPU等待硬件I/O时,所占用CPU百分比.
%idle:CPU空闲时间的百分比.
Device段段为设备信息(上图中有两个盘vda与vdb):
tps: 每秒钟发送到的I/O请求数.
Blk_read/s: 每秒读取的block数.
Blk_wrtn/s: 每秒写入的block数.
Blk_read: 读入的block总数.
Blk_wrtn: 写入的block总数.
2.3 sar -d 1 1
sar -d表示查看磁盘报告 1 1 表示间隔1s,运行1次
其实cpu、缓存区、文件读写、系统交换区等信息都可以通过该命令查看,只是选项不同,具体参见:http://blog.chinaunix.net/uid-23177306-id-2531032.html
第一个段为机器系统信息,同iostat
第二个段为每次运行的dev I/O信息,这里因为只运行一次,并有两个设备dev252-0与dev252-16:
tps:每秒从物理磁盘I/O的次数.多个逻辑请求会被合并为一个I/O磁盘请求,一次传输的大小是不确定的.
rd_sec/s:每秒读扇区数
wr_sec/s:每秒写扇区数
avgrq-sz:平均每次设备I/O操作的数据大小 (扇区)
avgqu-sz:平均I/O队列长度
await:为平均每次设备I/O操作的等待时间(单位ms),包括请求在队列中的等待时间和服务时间
svctm:为平均每次设备I/O操作的服务时间(单位ms)
%util:表示一秒中有百分之几的时间用于I/O操作
如果svctm的值与await很接近,表示几乎没有I/O等待,磁盘性能很好,如果await的值远高于svctm的值,则表示I/O队列等待太长,系统上运行的应用程序将变慢。
如果%util接近100%,表示磁盘产生的I/O请求太多,I/O系统已经满负荷的在工作,该磁盘请求饱和,可能存在瓶颈。idle小于70% I/O压力就较大了,也就是有较多的I/O。引用[1]
同时可以结合vmstat 查看b参数(等待资源的进程数)和wa参数(IO等待所占用的CPU时间的百分比,高过30%时IO压力高)。引用[1]
3. 分析
表示系统磁盘空间正常,主要有以下规则:
I/O等待的请求比例 <= 20%
提高命中率的一个简单方式就是增大文件缓存区面积,缓存区越大预存的页面就越多,命中率也越高。
Linux 内核希望能尽可能产生次缺页中断(从文件缓存区读),并且能尽可能避免主缺页中断(从硬盘读),这样随着次缺页中断的增多,文件缓存区也逐步增大,直到系统只有少量可用物理内存的时候 Linux 才开始释放一些不用的页。引用[1]
网络I/O
1.说明
如果服务器网络连接过多,那么会造成大量的数据包在缓冲区长时间得不到处理,一旦缓冲区不足,便会造成数据包丢失问题,对于TCP,数据包丢失便会进行重传,这有会导致大量的重传;对于UDP,数据包丢失不会进行重传,那么数据便会丢失。因此,服务器的网络连接不宜过多,需要进行监控。
服务器一般接收UDP与TCP请求,都是无状态连接,TCP(传输控制协议)是一种提供可靠的数据传输协议,UDP(用户数据报协议)是一种面向无连接的协议,即其传输简单但不可靠。关于它们二者之间的区别,可以查阅相关资料。
2.查看命令
2.3 netstat
2.3.1 UDP
(1) netstat -ludp | grep udp
Proto:协议名
Recv-Q:收到的请求个数
Send-Q:发送的请求个数
Local Address:本地地址与端口
Foreign Address:远程地址与端口
State:状态
PID/Program name:进程ID与进程名
(2) netstat -su 进一步查看UDP接收的数据包情况
画圈的便是UDP数据包丢失统计,该项值增加了,说明存在udp数据包丢失,即网卡收到了,但是应用层没有来得及处理而造成的丢包。
2.3.2 TCP
(1) netstat
各字段含义同UDP
(2) 查看重传率
因为TCP是可靠传输协议,如果数据包丢失会进行重传,因此TCP需要查看其重传率.
cat /proc/net/snmp | grep Tcp
那么重传率为RetransSegs/OutSegs
3. 分析
UDP丢包率或者TCP重传率不能高于多少,这两个值由系统开发定义,此处,拍脑袋决定UDP包丢包率与TCP包重传率不能超过1%/s。
连接数
1.说明
对于每一台服务器,都应该限制同时连接数,但是这个阈值又不好确定,因此当监测到系统负载过重时,然后取其连接数,这个值便可作为参考值。
2. 命令
2.1 netstat
netstat -na | sed -n ‘3,$p’ |awk ‘{print $5}’ | grep -v 127\.0\.0\.1 | grep -v 0\.0\.0\.0 | wc -l
3. 分析
系统负载过重时,该值作为服务器的峰值参考值。
如果超过1024报警
文件句柄数
1.说明
文件句柄数即当前打开的文件数,对于linux,系统默认支持的最大句柄数是1024,当然每个系统可以不一样,也可以修改,最大不能超过无符号整型最大值(65535),可以使用ulimit -n命令进行查看,即因此如果同时打开的文件数超过这个数便会发生异常。因此这个指标也需要进行监控。
2.查看命令
2.1 lsof
lsof -n | awk ‘{print $1,$2}’ | sort | uniq -c | sort -nr
三列分别是打开的文件句柄数, 进程名,进程号
3. 分析
将所有的行的第一列相加便是系统目前打开的文件句柄数num,如果num<=max_num*85%则报警。
性能指标总结
1.CPU
CPU利用率:us <= 70,sy <= 35,us + sy <= 70。
上下文切换:与CPU利用率相关联,如果CPU利用率状态良好,大量的上下文切换也是可以接受的。
可运行队列:每个处理器的可运行队列<=3个线程。
2.Memory
swap in (si) == 0,swap out (so) == 0
可用内存/物理内存 >= 30%
3.Disk
Use% <= 90%
4.Disk I/O
I/O等待的请求比例 <= 20%
5.Network I/O
UDP包丢包率与TCP包重传率不能超过1%/s。
6.Connect Num
<= 1024
7.File Handle Num
num/max_num <= 90%
总结
脚本检测nginx、tomcat与webapp运行异常日志(包括nginx与tomcat是否正在运行)与服务器性能七个指标,一旦发现异常信息和性能超标,那么马上发送邮件给管理员,也可以使用云监控push给管理员的云账号。